Modeling Spoken Language Beyond Text
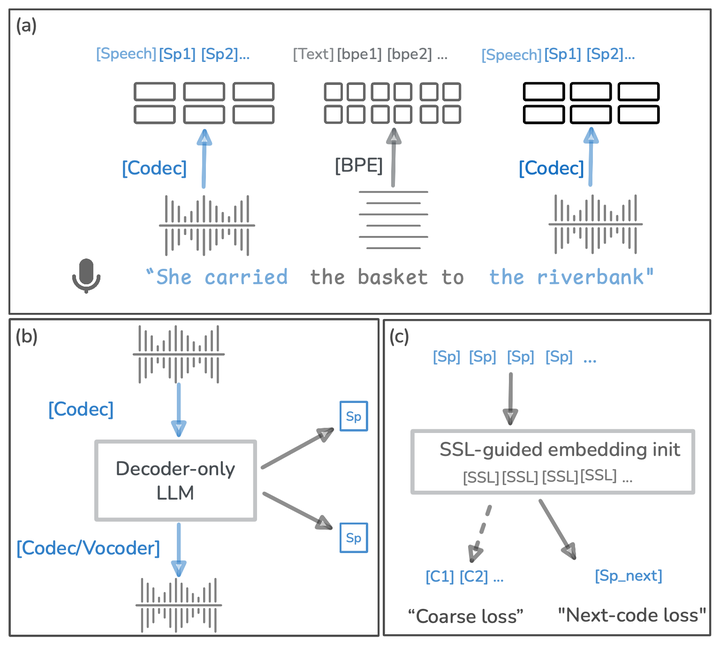
We develop models that learn language directly from speech rather than text. By focusing on acoustic consistency and capturing prosody, disfluencies, and non-verbal cues, our work aims to make spoken language understanding more natural and representative of how people communicate across different languages and speakers. These approaches open paths toward richer human–AI interaction and future applications in domains such as clinical communication, where vocal nuance carries critical context. We also study language models for resource-constrained devices, enabling efficient and accessible AI that can operate on mobile and edge systems. (read more here: click here )