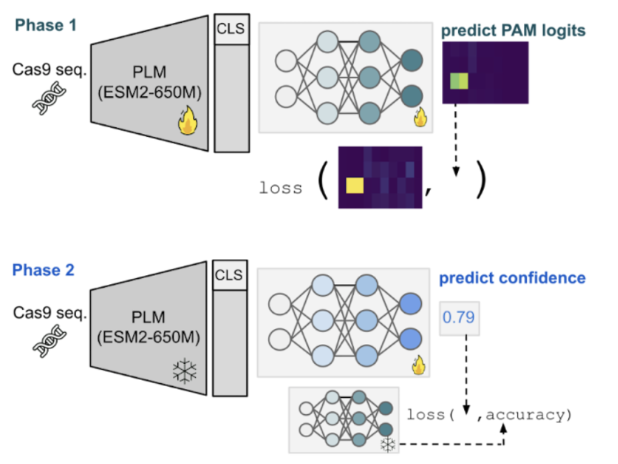
This project mines extensive metagenomic sequence data (CRISPR-PAMdb) to train machine learning models using protein language model representations to predict Cas9 PAM motifs. By identifying novel target-adjacent motifs, the resulting model, CICERO, predicts potential expansions of the targeting scope of existing CRISPR-Cas systems beyond canonical PAMs. The open-source data and model provide a framework for systematically mining natural sequence diversity to support the development of more versatile gene-editing tools. (read more here: link )
Code for CRISPR-PAMdb and CICERO: click here